스케일링
데이터의 값 범위를 조절하여 동일한 척도로 맞추는 노드입니다.
설명
스케일링은 데이터의 값 범위를 조절하는 과정으로, 다양한 변수 간에 공평한 비교를 가능하게 합니다.
대표적인 기법으로는 표준 정규화와 최소-최대 정규화가 있습니다.
스케일링을 통해 모델 학습 시 데이터 특성 간의 비교가 향상되며, 이상치의 영향을 줄이고 모델의 성능을 향상시킬 수 있습니다.
포트 구성
입력 포트
- 데이터셋: 스케일링할 데이터셋
출력 포트
- 데이터셋: 스케일링이 적용된 데이터셋
속성
다중 열 선택
스케일링을 적용할 열을 선택합니다.
여러 개의 열을 동시에 선택할 수 있습니다.
스케일링 방법 선택
데이터를 조정하는 방식을 선택합니다.
- 표준 정규화: 데이터의 평균을 0, 표준편차를 1로 조정하여 데이터를 표준 정규 분포에 가깝게 만듭니다
- 최소-최대 정규화: (변수 - 최솟값) / (최댓값 - 최솟값)의 식으로 계산하여 데이터를 0과 1 사이의 값으로 조정합니다
이상치를 1.5 IQR로 변환하시겠습니까? (최소-최대 정규화 선택 시)
최소-최대 정규화 선택 시 나타나는 옵션입니다.
이상치를 IQR(Interquartile Range, 사분위수 범위)의 1.5배 기준으로 변환할지 선택합니다.
활성화하면 극단적인 값의 영향을 줄일 수 있습니다.
예제
직원 데이터의 나이, 연봉, 근속년수를 동일한 척도로 맞추는 예제입니다.
원본 데이터는 나이(25-45), 연봉(3000-7000만원), 근속년수(1-9년)로 척도가 서로 다릅니다.
최소-최대 정규화
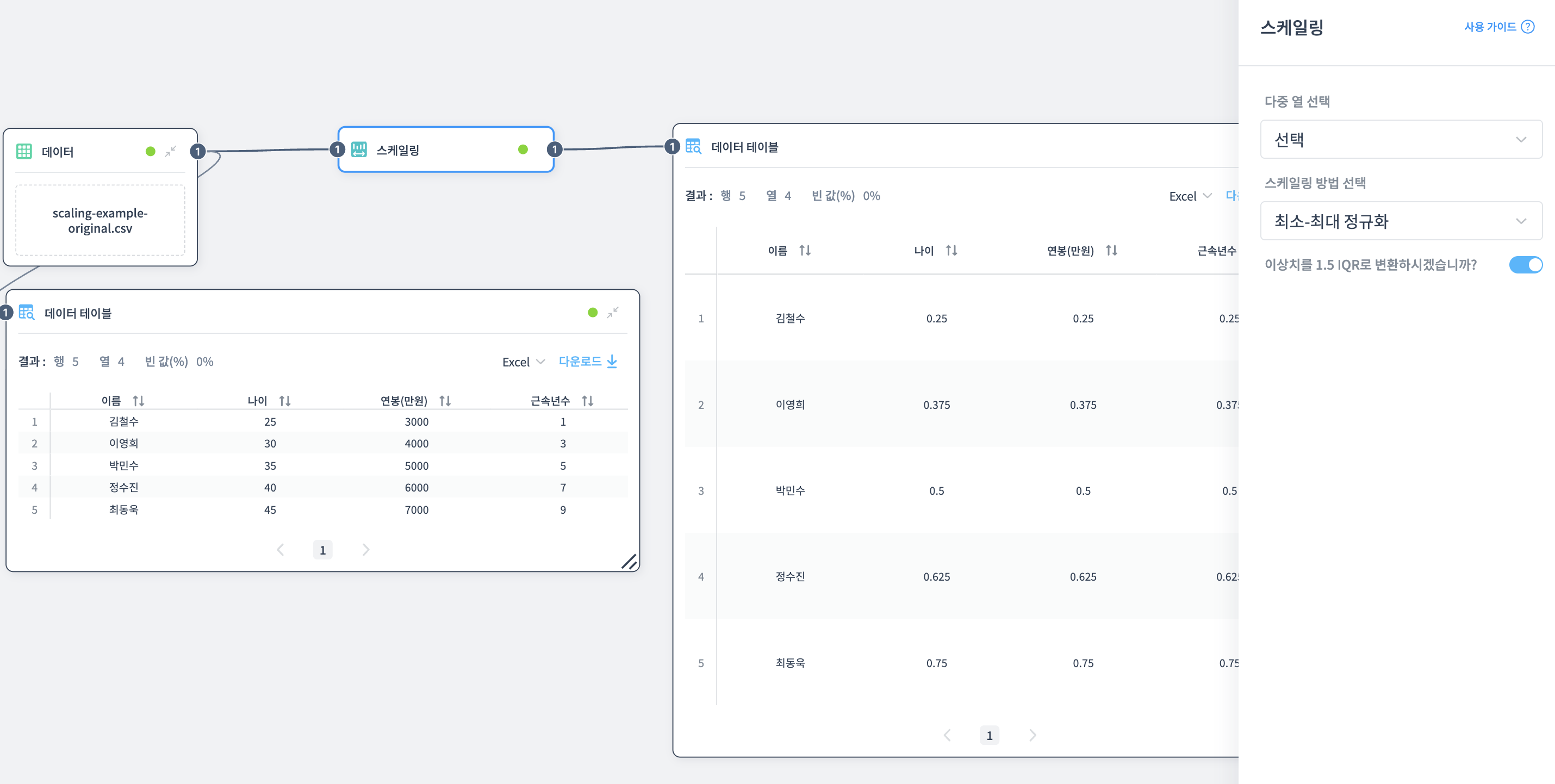
모든 값이 0-1 사이로 조정되어 동일한 척도로 비교할 수 있습니다.
표준 정규화
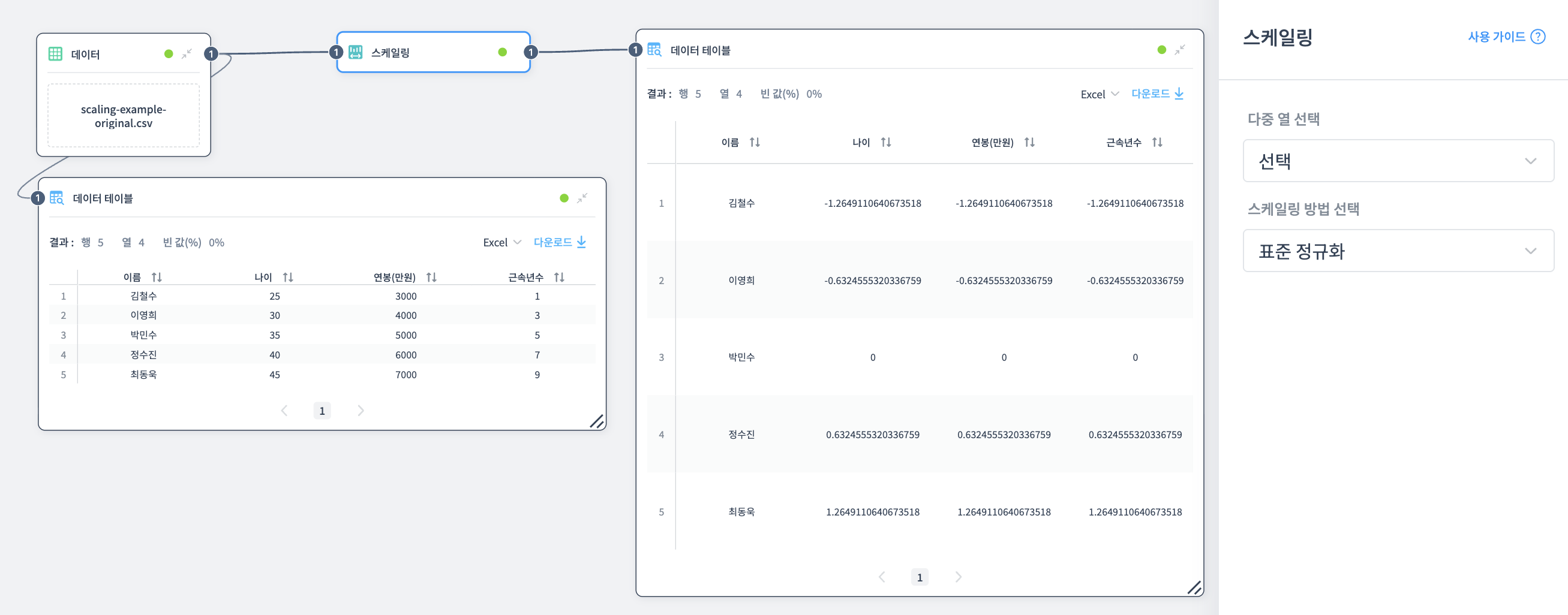
평균을 중심(0)으로 표준편차(1) 단위로 변환되어 각 값이 평균에서 얼마나 떨어져 있는지 비교할 수 있습니다.