랜덤 포레스트
다수의 결정 트리를 병렬로 학습하여 더 정확한 예측을 제공하는 앙상블 학습 모델입니다.
설명
랜덤 포레스트는 여러 개의 결정 트리를 독립적으로 학습시키고, 그 결과를 종합하여 최종 예측을 수행하는 앙상블 기법입니다.
각 트리는 부트스트랩 샘플링으로 생성된 서로 다른 데이터셋과 무작위로 선택된 특성으로 학습하여 다양성을 확보합니다.
개별 트리의 예측을 투표(분류) 또는 평균(회귀)하여 과적합을 방지하고 안정적인 예측 성능을 제공합니다.
포트 구성
입력 포트
없음
출력 포트
- 미학습 모델: 학습되지 않은 랜덤 포레스트 모델 (학습 노드에 연결하여 사용)
속성
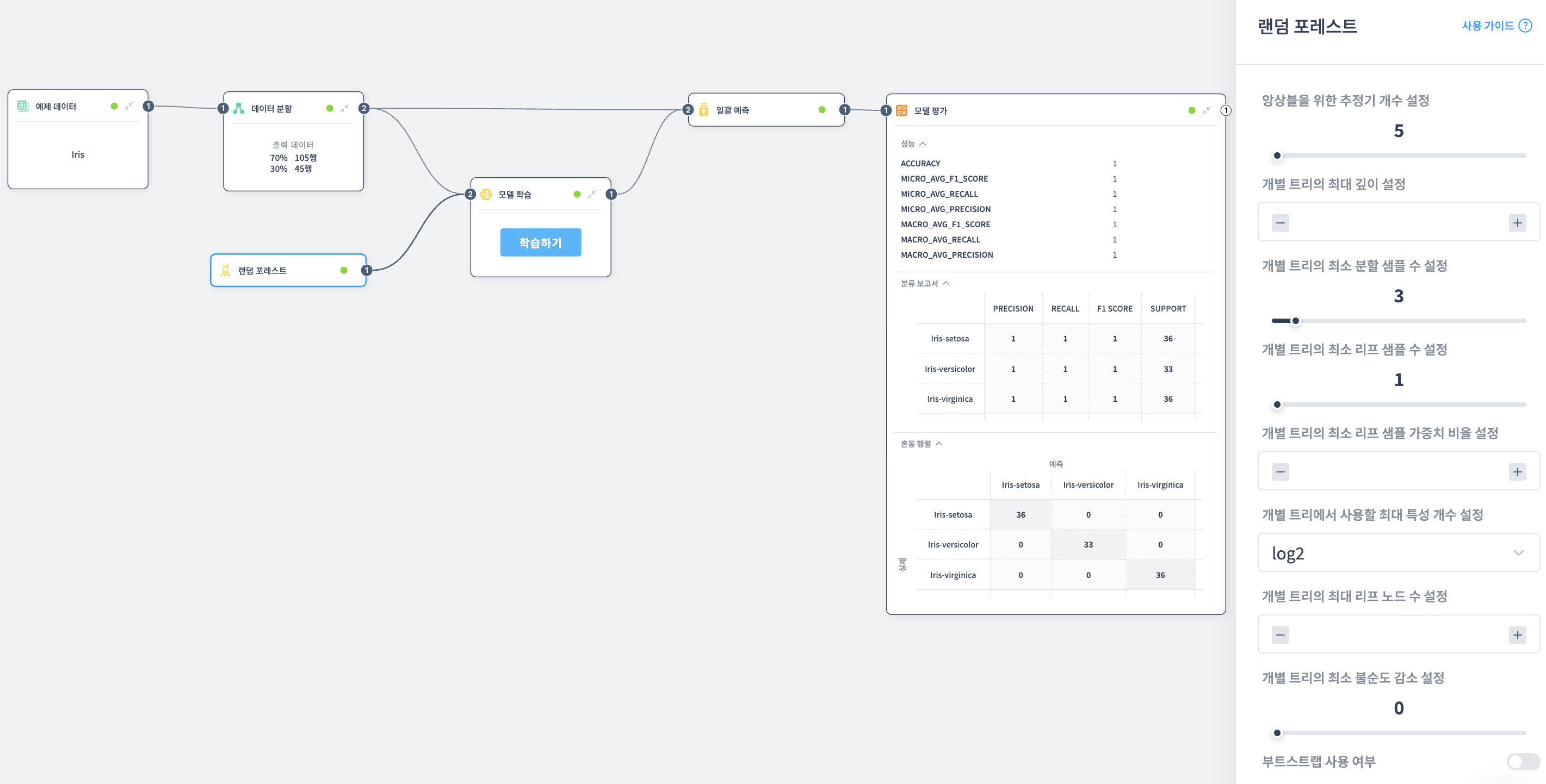
앙상블을 위한 추정기 개수 설정
앙상블에 사용할 결정 트리의 개수를 설정합니다.
- 큰 값: 모델의 성능 향상, 계산 비용과 메모리 사용량 증가
- 작은 값: 성능이 떨어질 수 있음
개별 트리의 최대 길이 설정
각 트리의 최대 깊이를 설정합니다.
- 큰 값: 모델이 복잡해짐 (세밀한 학습)
- 작은 값: 모델이 단순해짐 (과적합 방지)
개별 트리의 최소 분할 샘플 수 설정
노드를 분할하기 위해 필요한 최소 데이터 샘플 수를 설정합니다.
- 높은 값: 모델이 단순해짐 (과적합 방지)
- 낮은 값: 모델이 복잡해짐 (세밀한 분할)
개별 트리의 최소 리프 샘플 수 설정
리프 노드가 되기 위해 필요한 최소 샘플 수를 설정합니다.
- 높은 값: 모델이 단순해짐
- 낮은 값: 모델이 복잡해짐
개별 트리의 최소 리프 샘플 가중치 비율 설정
각 리프에 할당되는 최소 가중치의 합을 설정합니다.
- 높은 값: 불필요한 작은 리프 생성 방지, 성능 향상
- 낮은 값: 모델 성능이 떨어질 수 있음
개별 트리에서 사용할 최대 특성 개수 설정
각 트리에서 사용할 수 있는 최대 특성(피처) 수를 설정합니다.
- auto: 자동으로 설정 (제한 없음, 모든 특성 사용)
- log2: 특성 수의 log2 값으로 제한 (예: 16개 특성 → 최대 4개)
- sqrt: 특성 수의 제곱근으로 제한 (예: 16개 특성 → 최대 4개)
작은 값: 과적합 방지, 트리 간 다양성 증가 큰 값: 복잡한 패턴 학습, 과적합 위험
개별 트리의 최대 리프 노드 수 설정
트리에서 생성할 수 있는 최대 리프 노드 수를 설정합니다.
- 작은 값: 모델이 단순해짐
- 큰 값: 모델이 복잡해짐
개별 트리의 최소 불순도 감소 설정
분할을 수행하기 위한 최소 불순도 감소량을 설정합니다.
- 작은 값: 모델이 단순해짐
- 큰 값: 모델이 복잡해짐
부트스트랩 사용 여부
원본 데이터에서 중복을 허용하여 샘플을 추출할지 선택합니다.
- 사용: 각 트리가 서로 다른 데이터셋으로 학습, 앙상블 다양성 증가
- 미사용: 중복 없이 독립적인 샘플 사용, 앙상블 다양성 감소
사용 방법
- 랜덤 포레스트 노드를 캔버스에 추가합니다
- 원하는 속성을 설정합니다 (추정기 개수, 트리 깊이 등)
- 출력된 미학습 모델을 모델 학습 노드에 연결합니다
- 학습용 데이터셋을 모델 학습 노드에 연결합니다
- 학습이 완료되면 학습된 모델을 일괄 예측 노드와 모델 평가 노드에서 사용할 수 있습니다
예제