유사도 군집화
데이터 간의 유사도를 기반으로 군집을 형성하는 클러스터링 모델입니다.
설명
유사도 군집화는 데이터 포인트 간의 유사도를 계산하여, 설정된 임계값 이상의 유사도를 가진 데이터들을 같은 군집으로 묶는 알고리즘입니다.
K-평균 군집화와 달리 군집 개수를 미리 지정하지 않으며, 데이터의 유사도에 따라 자동으로 군집이 형성됩니다.
전이성 옵션을 사용하면 간접적으로 연결된 데이터들도 같은 군집으로 묶을 수 있습니다.
포트 구성
입력 포트
- 데이터셋: 군집화할 데이터셋 (숫자형 열 포함)
출력 포트
- 데이터셋: 군집 번호가 추가된 데이터셋
출력 데이터셋
| 컬럼명 | 설명 |
|---|---|
| (원본 데이터) | 입력 데이터의 모든 열 |
| cluster_id | 할당된 군집 번호 (0, 1, 2, ...) |
| count | 해당 군집에 속한 데이터의 총 개수 |
속성
임계값
데이터 간의 유사도가 이 값 이상이면 같은 군집으로 묶습니다 (0-1 사이 값).
값이 클수록 더 유사한 데이터만 묶이고, 작을수록 더 많은 데이터가 묶입니다.
데이터 특성에 따라 적절한 임계값을 찾아 설정하세요.
전이성
간접적으로 연결된 데이터들을 같은 군집으로 묶을지 결정합니다.
- 활성화: A와 B가 유사하고, B와 C가 유사하면, A와 C도 같은 군집으로 묶음
- 더 큰 군집 형성
- 간접적 연결 고려
- 비활성화: 직접적으로 유사한 데이터만 같은 군집으로 묶음
- 더 작고 밀집된 군집 형성
- 엄격한 유사도 기준
사용 방법
- 유사도 군집화 노드를 캔버스에 추가합니다
- 군집화할 데이터셋을 연결합니다
- 임계값을 설정합니다
- 전이성 옵션을 선택합니다
- 간접 연결도 묶으려면: 활성화
- 직접 유사한 것만 묶으려면: 비활성화
- 노드를 실행하면 군집 번호가 추가된 데이터가 출력됩니다
- 산점도 노드로 군집 결과를 시각화할 수 있습니다
예제
비슷한 뉴스 기사 제목 제거하기
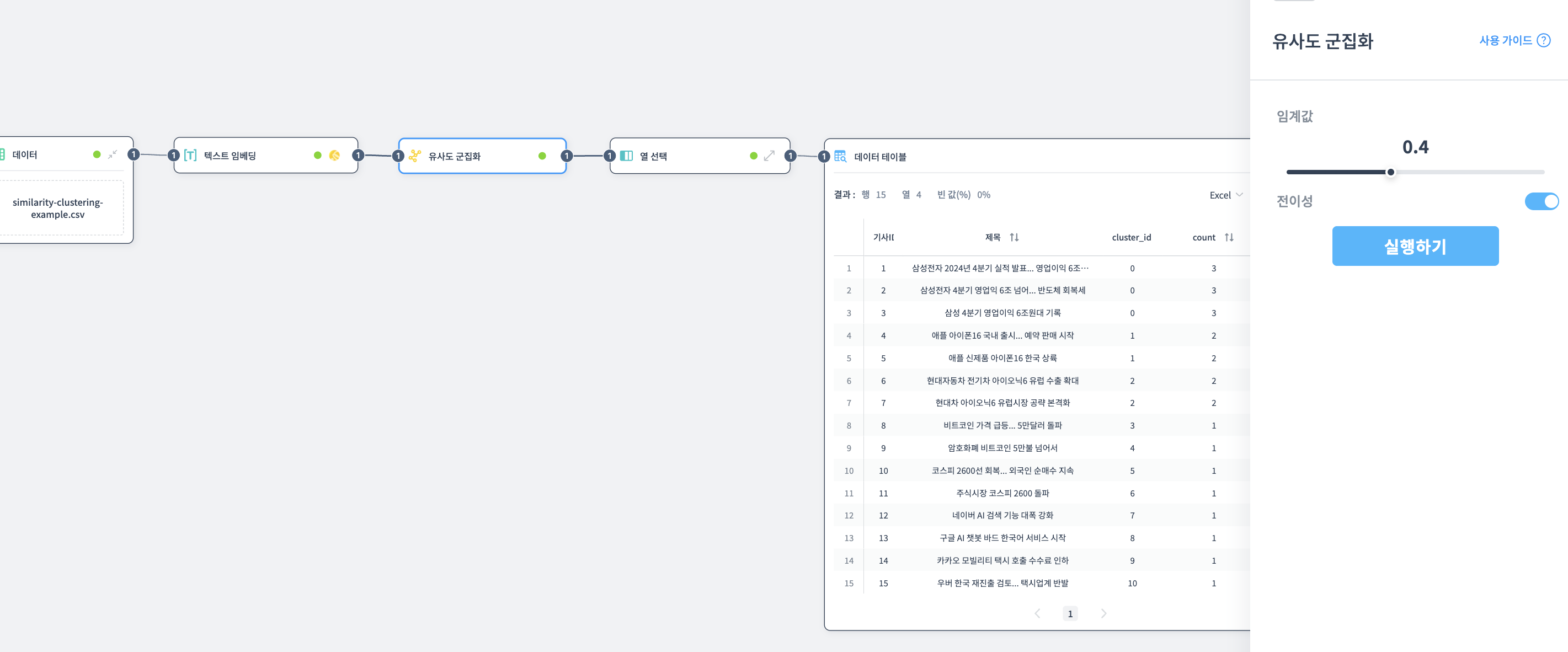
중복된 내용의 뉴스 기사를 유사도 기반으로 군집화하여 제거하는 예제입니다.
데이터:
15개의 뉴스 기사 제목 (실제로는 같은 내용의 기사가 여러 개 포함)
| 기사ID | 제목 |
|---|---|
| 1 | 삼성전자 2024년 4분기 실적 발표... 영업이익 6조원 돌파 |
| 2 | 삼성전자 4분기 영업익 6조 넘어... 반도체 회복세 |
| 3 | 삼성 4분기 영업이익 6조원대 기록 |
| 4 | 애플 아이폰16 국내 출시... 예약 판매 시작 |
| 5 | 애플 신제품 아이폰16 한국 상륙 |
| ... | ... |
노드 연결:
데이터 테이블 → 텍스트 임베딩 → 유사도 군집화 → 열 선택 → 데이터 테이블
각 노드 설정:
-
텍스트 임베딩 노드:
- 대상 열 선택: 제목
- 선택한 대상 열을 삭제: 체크 해제 (제목도 함께 보기)
-
유사도 군집화 노드:
- 임계값: 0.4
- 전이성: 활성화
-
열 선택 노드:
- 기사ID, 제목, cluster_id, count 선택