그래디언트 부스팅
손실을 최소화하는 방향으로 연속적으로 모델을 개선하는 앙상블 학습 모델입니다.
설명
그래디언트 부스팅은 여러 개의 약한 학습기(주로 결정 트리)를 순차적으로 결합하여 강력한 예측 모델을 만드는 앙상블 기법입니다.
각 단계에서 이전 모델의 오차를 보완하는 방식으로 학습하며, 손실 함수를 최소화하는 방향으로 모델을 개선합니다.
높은 예측 정확도로 분류와 회귀 문제에 널리 사용됩니다.
포트 구성
입력 포트
없음
출력 포트
- 미학습 모델: 학습되지 않은 그래디언트 부스팅 모델 (학습 노드에 연결하여 사용)
속성
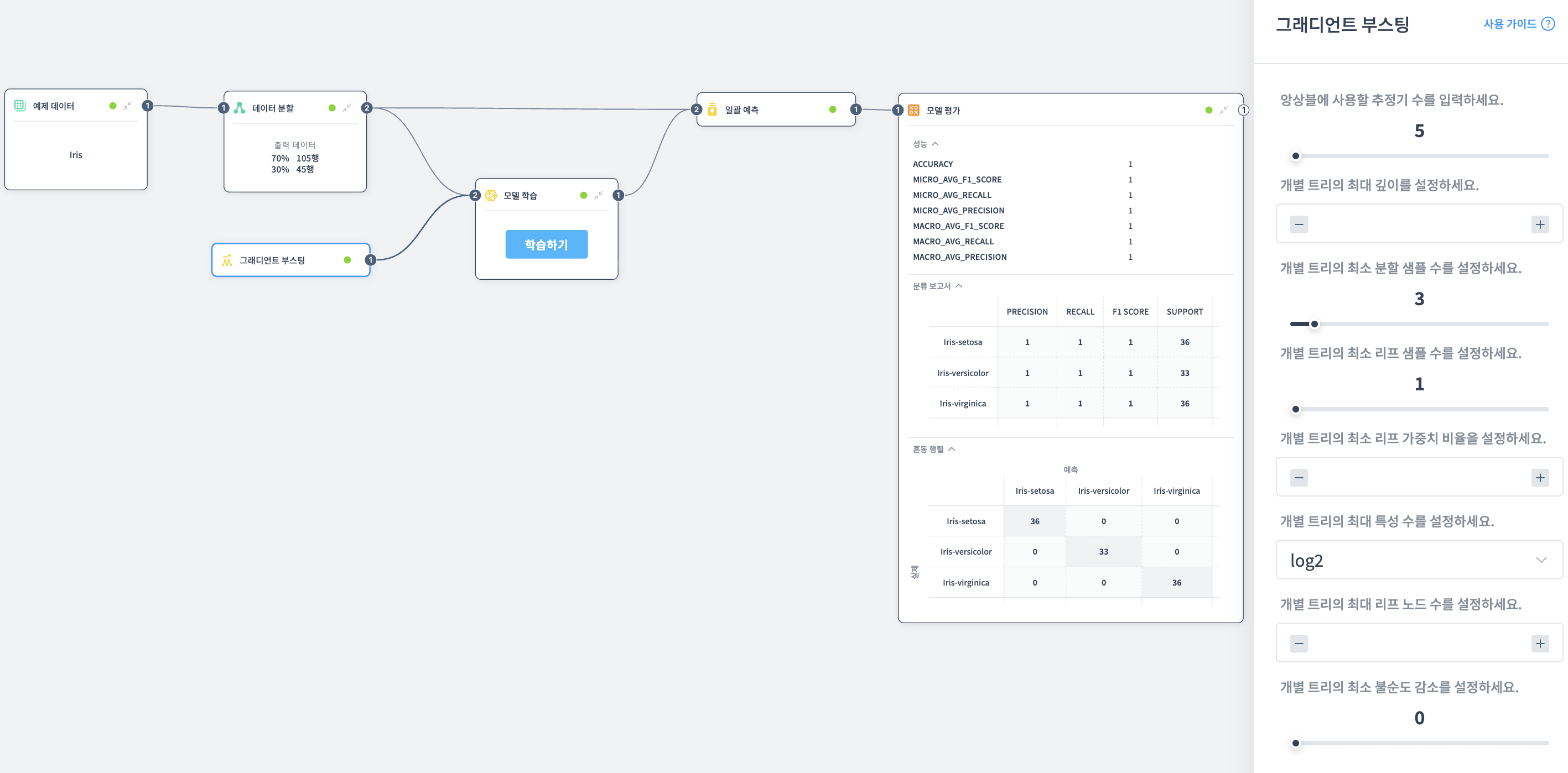
앙상블에 사용할 추정기 수 입력
앙상블에 사용할 결정 트리의 개수를 설정합니다.
- 큰 값: 모델의 복잡성과 성능이 향상됨
- 작은 값: 성능이 떨어질 수 있음
개별 트리의 최대 길이 설정
각 트리의 최대 깊이를 설정합니다.
- 큰 값: 모델이 복잡해짐 (세밀한 학습)
- 작은 값: 모델이 단순해짐 (과적합 방지)
개별 트리의 최소 분할 샘플 수 설정
노드를 분할하기 위해 필요한 최소 데이터 샘플 수를 설정합니다.
- 높은 값: 모델이 단순해짐 (과적합 방지)
- 낮은 값: 모델이 복잡해짐 (세밀한 분할)
개별 트리의 최소 리프 샘플 수 설정
리프 노드가 되기 위해 필요한 최소 샘플 수를 설정합니다.
- 높은 값: 모델이 단순해짐
- 낮은 값: 모델이 복잡해짐
개별 트리의 최소 리프 가중치 비율 설정
각 리프에 할당되는 최소 가중치의 합을 설정합니다.
- 높은 값: 불필요한 작은 리프 생성 방지, 성능 향상
- 낮은 값: 모델 성능이 떨어질 수 있음
개별 트리의 최대 특성 수 설정
각 트리에서 사용할 수 있는 최대 특성(피처) 수를 설정합니다.
- auto: 자동으로 설정 (제한 없음, 모든 특성 사용)
- log2: 특성 수의 log2 값으로 제한 (예: 16개 특성 → 최대 4개)
- sqrt: 특성 수의 제곱근으로 제한 (예: 16개 특성 → 최대 4개)
작은 값: 과적합 방지, 안정성 증가 큰 값: 복잡한 패턴 학습, 과적합 위험
개별 트리의 최대 리프 노드 수 설정
트리에서 생성할 수 있는 최대 리프 노드 수를 설정합니다.
- 작은 값: 모델이 단순해짐
- 큰 값: 모델이 복잡해짐
개별 트리의 최소 불순도 감소 설정
분할을 수행하기 위한 최소 불순도 감소량을 설정합니다.
- 작은 값: 모델이 단순해짐
- 큰 값: 모델이 복잡해짐
사용 방법
- 그래디언트 부스팅 노드를 캔버스에 추가합니다
- 원하는 속성을 설정합니다 (추정기 수, 트리 깊이 등)
- 출력된 미학습 모델을 모델 학습 노드에 연결합니다
- 학습용 데이터셋을 모델 학습 노드에 연결합니다
- 학습이 완료되면 학습된 모델을 일괄 예측 노드와 모델 평가 노드에서 사용할 수 있습니다
예제