텍스트 임베딩
텍스트 데이터를 수치 벡터로 변환하는 노드입니다.
설명
텍스트 임베딩 노드는 텍스트 데이터를 수치 벡터로 변환합니다.
변환된 벡터는 텍스트의 의미를 수치적으로 표현하여 머신러닝 모델의 입력 데이터로 사용할 수 있습니다.
포트 구성
입력 포트
- 데이터셋: 텍스트가 포함된 데이터셋
출력 포트
- 데이터셋: 벡터화된 텍스트가 포함된 데이터
속성
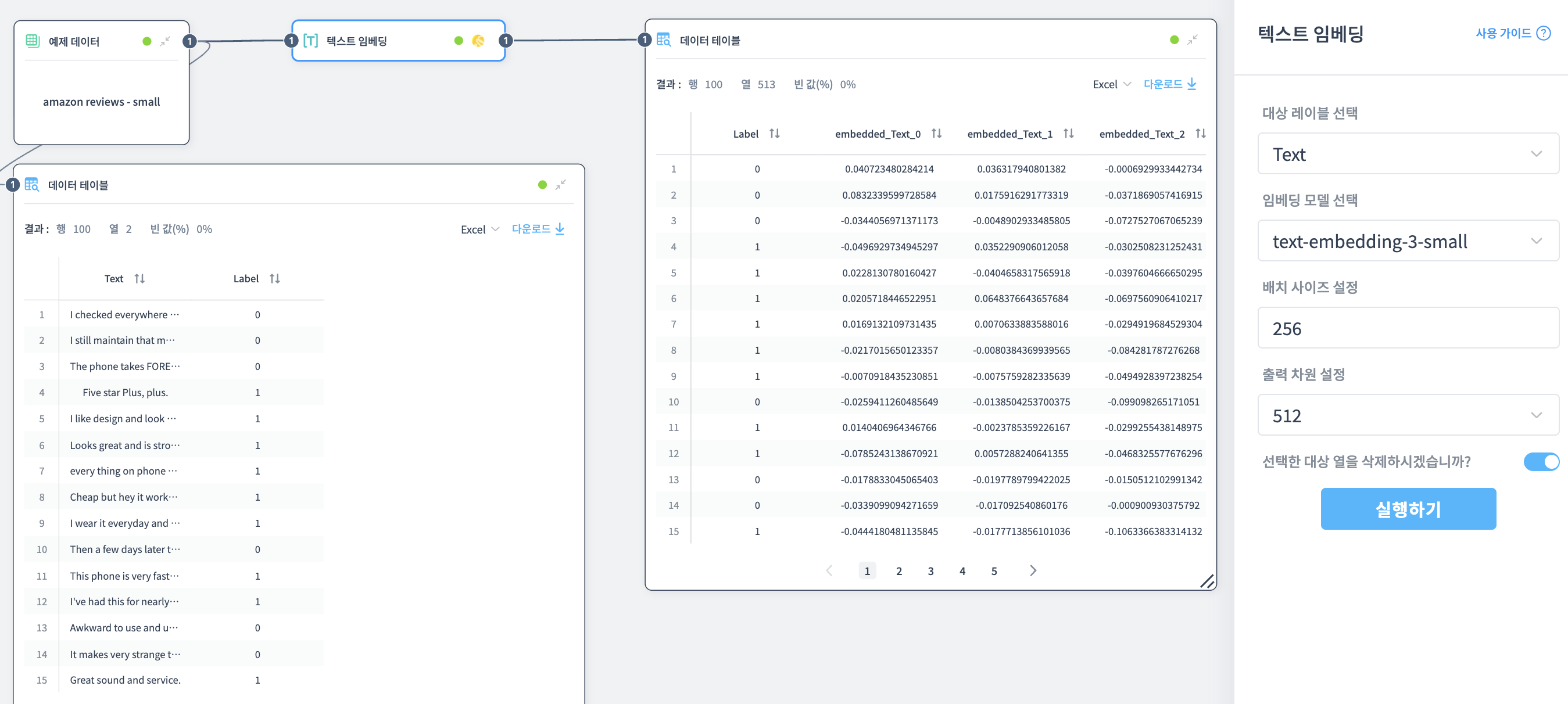
대상 테이블 선택
임베딩할 텍스트가 포함된 열을 선택합니다.
임베딩 모델 선택
텍스트 임베딩 모델을 선택합니다.
모델에 따라 텍스트의 의미를 벡터로 표현하는 방식이 달라집니다.
배치 사이즈 설정
임베딩 시 배치 사이즈를 설정합니다.
배치 사이즈가 클수록 처리 속도는 빠르지만 메모리 사용량이 증가합니다.
권장 설정:
- 소량 데이터(100개 미만): 16-32
- 중간 데이터(100-1000개): 32-64
- 대량 데이터(1000개 이상): 64-128
출력 차원 설정
임베딩 벡터의 차원을 설정합니다.
512 또는 1536 중 선택할 수 있습니다.
선택 가이드:
- 512: 더 적은 메모리 사용, 빠른 처리 속도, 일반적인 텍스트 분류/검색에 적합
- 1536: 더 정확한 의미 표현, 복잡한 문맥 이해에 적합, OpenAI 임베딩 표준 차원
대부분의 경우 512 차원으로 충분합니다.
선택한 대상 열을 삭제
출력 데이터셋에 임베딩 전의 텍스트를 포함할 지 선택합니다.
활성화하면 원본 텍스트 열은 삭제되고 벡터 데이터만 남습니다.
사용 방법
- 노드를 캔버스에 추가합니다
- 텍스트가 포함된 데이터셋을 입력 포트에 연결합니다
- 속성에서 텍스트가 있는 열을 선택합니다
- 임베딩 모델을 선택합니다
- 배치 사이즈와 출력 차원을 설정합니다
- 필요한 경우 선택한 대상 열을 삭제 옵션을 설정합니다
- 노드를 실행하면 텍스트가 벡터로 변환됩니다
예제