텍스트 전처리
텍스트 데이터를 정제하고 분석에 적합하게 변환하는 노드입니다.
설명
텍스트 전처리 노드는 텍스트 데이터를 정제하고 분석에 적합한 형태로 변환합니다.
불용어 제거, N-gram 생성 등의 전처리 기법을 적용하여 텍스트 분석의 정확도를 높일 수 있습니다.
포트 구성
입력 포트
- 데이터셋: 텍스트가 포함된 데이터셋
출력 포트
- 데이터셋: 전처리된 텍스트가 포함된 데이터
속성
대상 열 선택
전처리할 텍스트가 포함된 열을 선택합니다.
불용어 제거
분석에 큰 의미가 없는 단어를 제거합니다.
예시:
- 원본: "나는 오늘 영화를 봤다"
- 불용어 제거 후: "오늘 영화 봤다"
"나는", "을" 같은 의미 없는 조사가 제거됩니다.
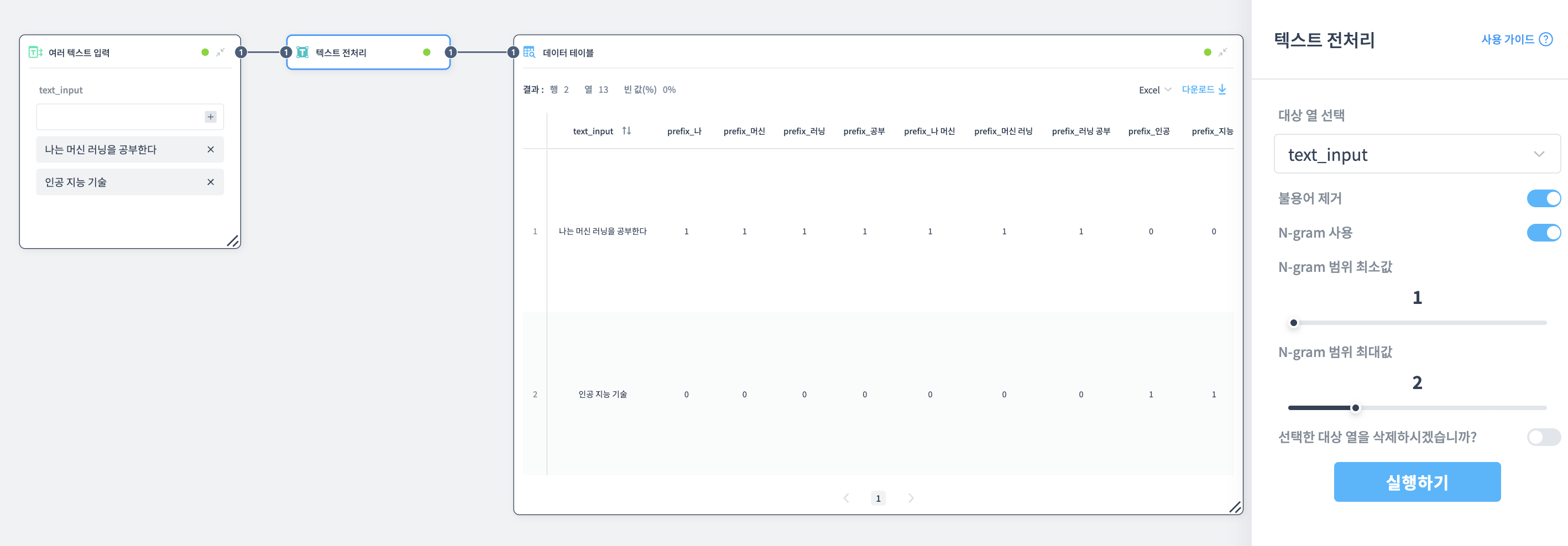
N-gram 사용
텍스트를 단어 단위로 분리하고, 각 단어와 단어 조합을 별도의 열로 변환합니다.
예시: "나는 머신 러닝을 공부한다" (불용어 제거 후: "나 머신 러닝 공부")
N-gram 미사용:
원본 텍스트 그대로 유지
N-gram 사용 (최소 1, 최대 2):
생성되는 열들:
- 1-gram:
prefix_나,prefix_머신,prefix_러닝,prefix_공부 - 2-gram:
prefix_나 머신,prefix_머신 러닝,prefix_러닝 공부
각 열의 값: 해당 n-gram이 텍스트에 있으면 1.0, 없으면 0.0
이렇게 텍스트가 숫자 데이터로 변환되어 머신러닝 모델의 입력으로 사용할 수 있습니다.
최소 N-gram 크기
최소 몇 개의 단어를 묶을지 설정합니다.
예시: "인공 지능 기술"
- 최소 1: "인공", "지능", "기술" (단어 하나씩도 포함)
- 최소 2: "인공 지능", "지능 기술" (2개 이상만)
최대 N-gram 크기
최대 몇 개의 단어를 묶을지 설정합니다.
예시: "인공 지능 기술"
- 최대 2: "인공 지능", "지능 기술" (최대 2개 단어 조합)
- 최대 3: "인공 지능 기술" (최대 3개 단어 조합까지 포함)
실제 설정 예시: "인공 지능 기술"이라는 문장
최소 1, 최대 2로 설정:
생성되는 열: prefix_인공, prefix_지능, prefix_기술, prefix_인공 지능, prefix_지능 기술
→ 1개 단어 열 + 2개 단어 조합 열 모두 생성
최소 2, 최대 3으로 설정:
생성되는 열: prefix_인공 지능, prefix_지능 기술, prefix_인공 지능 기술
→ 1개 단어 열은 제외, 2개와 3개 단어 조합 열만 생성
권장 설정:
- 일반적인 텍스트 분석: 최소 1, 최대 2
- 구문/표현 찾기: 최소 2, 최대 3
선택한 대상 열을 삭제
출력 데이터셋에 전처리 전의 원본 텍스트를 포함할지 선택합니다.
활성화하면 원본 텍스트 열은 삭제되고 전처리된 데이터만 남습니다.
사용 방법
- 노드를 캔버스에 추가합니다
- 텍스트가 포함된 데이터셋을 입력 포트에 연결합니다
- 속성에서 전처리할 텍스트 열을 선택합니다
- 불용어 제거 옵션을 설정합니다
- N-gram 사용 여부를 선택합니다
- N-gram 사용 시 최소/최대 크기를 설정합니다
- 필요한 경우 선택한 대상 열을 삭제 옵션을 설정합니다
- 노드를 실행하면 텍스트가 전처리됩니다
예제