표본 재추출
불균형한 데이터의 비율을 조정합니다.
입력 포트
데이터셋
출력 포트
데이터셋: 표본 재추출된 데이터셋
설명
데이터에서 특정 값이 너무 많거나 적을 때, 비율을 조정하여 균형을 맞춥니다.
예를 들어, 합격 1000명, 불합격 100명인 데이터가 있다면 불합격 데이터가 너무 적어서 학습이 어렵습니다. 이럴 때 표본 재추출을 사용합니다.
설정
1. 대상 레이블 선택
비율을 조정할 열을 선택합니다.
'Yes/No', '합격/불합격', '1/0' 처럼 두 가지 값만 있는 열을 선택할 수 있습니다.
2. 샘플 방법 선택
Under Sampling (언더 샘플링):
많은 쪽의 데이터를 줄입니다.
예: Yes 1000개, No 500개 → Yes를 줄여서 균형 맞추기
Over Sampling (오버 샘플링):
적은 쪽의 데이터를 늘립니다 (복제).
예: Yes 1000개, No 500개 → No를 복제해서 균형 맞추기
3. 샘플링 비율 설정
데이터를 얼마나 줄이거나 늘릴지 설정합니다.
Under Sampling (0 < 비율 < 1):
많은 쪽 데이터를 비율만큼 남깁니다.
예시:
- 원본: Yes 1000개, No 500개 (총 1500개)
- 비율 0.7로 Under Sampling 실행
- 결과: Yes 700개 (1000 × 0.7), No 500개 (총 1200개)
- Yes가 많았으므로 Yes를 70%만 남김
Over Sampling (비율 > 1):
적은 쪽 데이터를 비율만큼 늘립니다.
예시:
- 원본: Yes 1000개, No 500개 (총 1500개)
- 비율 1.5로 Over Sampling 실행
- 결과: Yes 1000개, No 750개 (500 × 1.5, 총 1750개)
- No가 적었으므로 No를 1.5배로 복제
예제
데이터 설명
은행의 대출 승인 데이터입니다.
- 총 100개의 대출 신청 데이터
- 승인: 75개
- 거절: 25개
거절 데이터가 승인 데이터의 1/3 밖에 안 돼서 불균형합니다. 이런 경우 모델이 거절을 잘 학습하지 못할 수 있습니다.
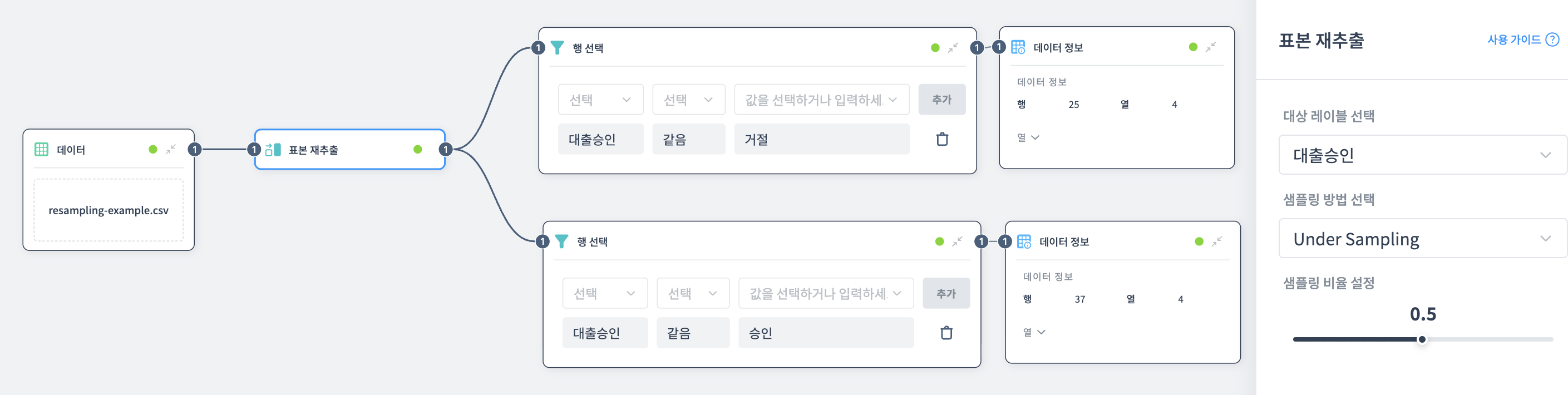
Under Sampling 예제
많은 쪽(승인)을 줄여서 균형을 맞춥니다.
노드 설정:
- 대상 레이블 선택: 대출승인
- 샘플 방법: Under Sampling
- 샘플링 비율: 0.5
결과:
- 승인: 37개 (75 × 0.5 = 37.5 → 내림)
- 거절: 25개 (그대로 유지)
- 총 데이터: 62개
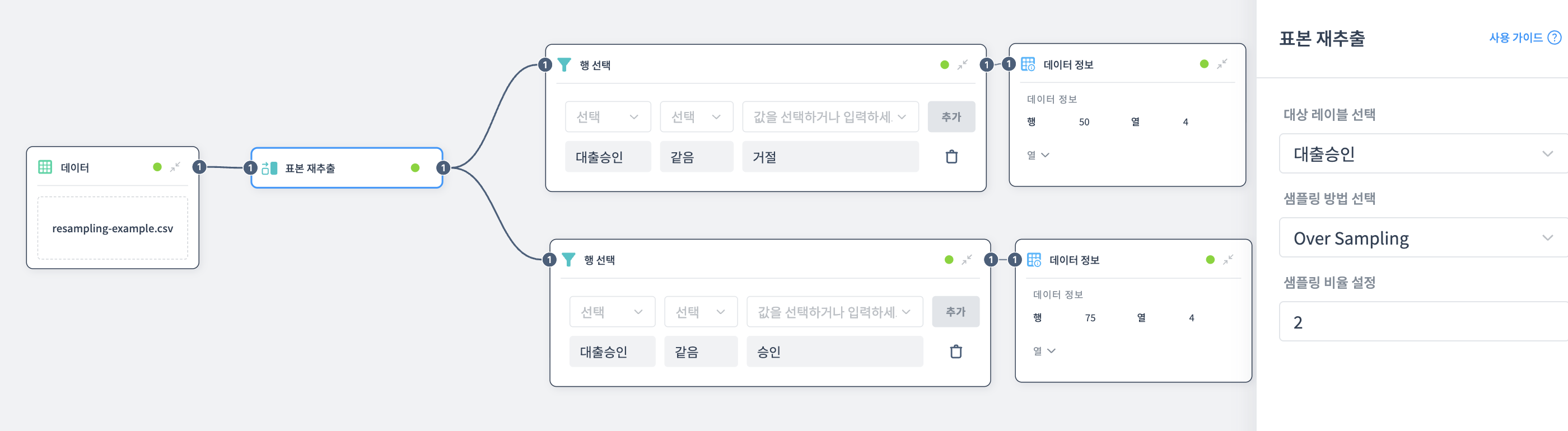
Over Sampling 예제
적은 쪽(거절)을 늘려서 균형을 맞춥니다.
노드 설정:
- 대상 레이블 선택: 대출승인
- 샘플 방법: Over Sampling
- 샘플링 비율: 2.0
결과:
- 승인: 75개 (그대로 유지)
- 거절: 50개 (25 × 2.0, 복제됨)
- 총 데이터: 125개