K-평균 군집화
데이터를 K개의 군집으로 분류하는 비지도 학습 모델입니다.
설명
K-평균 군집화는 데이터를 사전에 정의한 K개의 그룹(군집)으로 나누는 비지도 학습 알고리즘입니다.
각 데이터는 가장 가까운 중심점(centroid)을 기준으로 군집에 할당되며, 유사한 특성을 가진 데이터끼리 같은 군집으로 분류됩니다.
고객 세분화, 이미지 압축, 패턴 인식 등 다양한 분야에서 활용됩니다.
포트 구성
입력 포트
- 데이터셋: 군집화할 데이터셋
출력 포트
- 데이터셋 (Clustering Iteration): 각 데이터에 할당된 군집 번호가 포함된 데이터셋
- 데이터셋 (Clustering Centroids): 각 군집의 중심점 좌표가 포함된 데이터셋
속성
클러스터 개수
데이터를 나눌 클러스터의 개수를 설정합니다.
적절한 클러스터 개수는 데이터의 특성과 분석 목적에 따라 달라집니다.
초기화 방법
중심점의 초기 위치를 설정하는 방법을 선택합니다:
- k-means++: 초기 중심점을 서로 멀리 배치하여 더 나은 결과를 얻습니다 (권장)
- random: 무작위로 초기 중심점을 선택합니다
초기화 횟수
서로 다른 초기 중심점으로 알고리즘을 반복 실행할 횟수를 설정합니다.
여러 번 실행하여 가장 좋은 결과를 선택합니다. 일반적으로 10회 정도가 적절합니다.
최대 반복 횟수
알고리즘이 수렴하기 위한 최대 반복 횟수를 설정합니다.
일반적으로 100~300 사이의 값을 사용합니다.
출력 데이터셋
Clustering Iteration
각 반복 단계에서 데이터 포인트에 할당된 군집 번호를 보여주는 데이터셋입니다.
| 컬럼명 | 설명 |
|---|---|
| (원본 데이터 열들) | 입력 데이터의 모든 열 |
| cluster_iteration_01 | 첫 번째 반복에서 할당된 군집 번호 (0부터 시작) |
| cluster_iteration_02 | 두 번째 반복에서 할당된 군집 번호 |
| ... | ... |
| cluster_iteration_XX | XX 번째 반복에서 할당된 군집 번호 |
- 컬럼 개수 = 원본 데이터 열 개수 + 반복 횟수 (예: 2개 원본 열 + 5회 반복 = 7개 컬럼)
- 최종 군집 할당을 확인하려면 마지막
cluster_iteration_XX컬럼을 참고하면 됩니다
Clustering Centroids
각 군집의 중심점(centroid) 좌표를 포함하는 데이터셋입니다.
| 컬럼명 | 설명 |
|---|---|
| clusters | 군집 번호 (0, 1, 2, ...) |
| cluster_iteration | 반복 단계 (cluster_iteration_01, 02, 03, ...) |
| (원본 숫자 열들) | 각 군집의 중심점 값 (예: 월평균구매금액, 월방문횟수) |
- 총 행 수 = 군집 개수 × 반복 횟수 (예: 3개 군집 × 5회 = 15행)
- 최종 군집 중심점을 확인하려면 마지막
cluster_iteration값을 필터링하면 됩니다
사용 방법
- 노드를 캔버스에 추가합니다
- 군집화할 데이터셋을 입력 포트에 연결합니다
- 데이터에 ID나 이름 같은 고유 식별자가 있다면, 열 선택 노드로 숫자 데이터만 선택합니다
- 속성에서 클러스터 개수를 설정합니다
- 필요한 경우 초기화 방법, 초기화 횟수, 최대 반복 횟수를 조정합니다
- 노드를 실행하면 각 데이터에 군집 번호가 부여됩니다
- 출력된 모델은 새로운 데이터의 군집 예측에 사용할 수 있습니다
예제
온라인 쇼핑몰의 고객 40명을 구매 패턴에 따라 3개 그룹으로 나누는 예제입니다.
데이터
- 월평균구매금액: 30,000원 ~ 420,000원
- 월방문횟수: 1회 ~ 20회
노드 연결
데이터 테이블 → 열 선택 → K-평균 군집화
- 열 선택에서
고객ID제거,월평균구매금액,월방문횟수만 선택
K-평균 군집화 설정
- 클러스터 개수: 3
- 초기화 방법: k-means++
- 초기화 횟수: 10
- 최대 반복 횟수: 100
출력 결과
Clustering Iteration 출력
K-평균 군집화의 Clustering Iteration 출력 포트를 산점도 노드에 연결합니다.
산점도 설정:
- X축: 월평균구매금액
- Y축: 월방문횟수
- 속성 열: cluster_iteration_05
결과:
고객이 3개 군집으로 색상별로 분류됩니다:
- 군집 0 (빨간색): 일반 고객 - 중간 구매금액 + 중간 방문횟수
- 군집 1 (청록색): 잠재 고객 - 낮은 구매금액 + 낮은 방문횟수
- 군집 2 (보라색): VIP 고객 - 높은 구매금액 + 높은 방문횟수
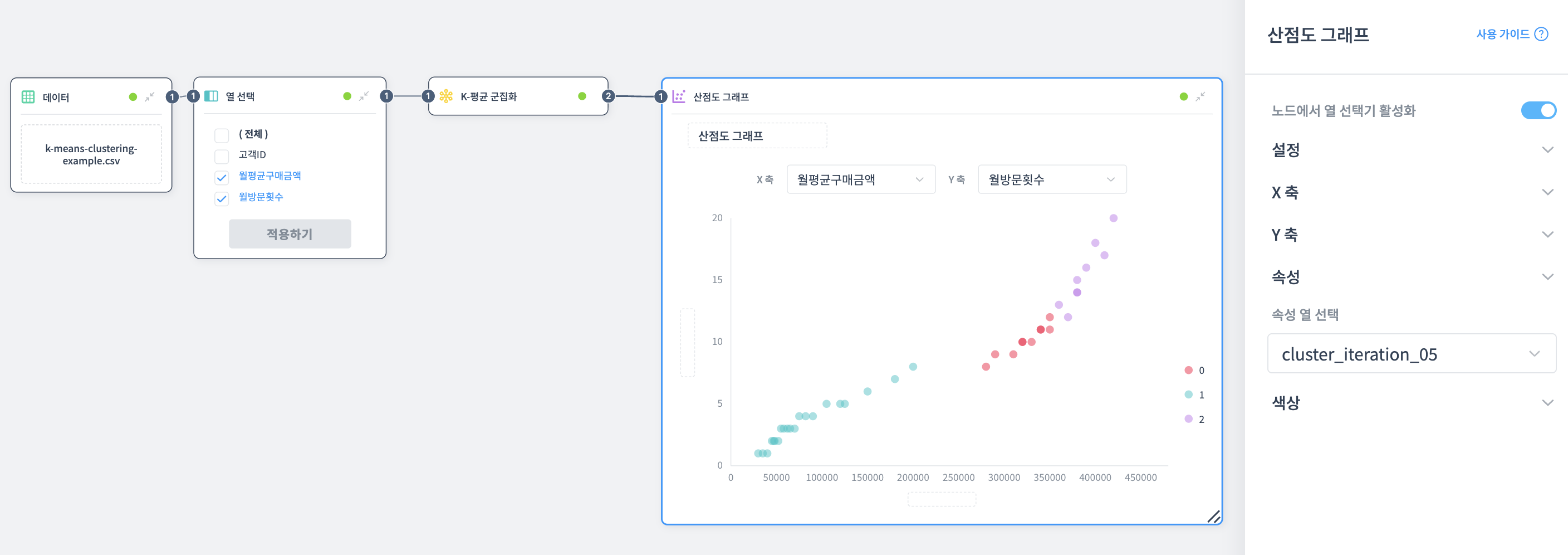
참고: cluster_iteration_01~04는 중간 과정이고, cluster_iteration_05가 최종 결과입니다.
Clustering Centroids 출력
K-평균 군집화의 Clustering Centroids 출력 포트를 데이터 테이블 노드에 연결합니다.
결과:
각 군집의 중심값(평균)을 확인할 수 있습니다:
- 군집 0 중심: 월평균구매금액 약 323,000원, 월방문횟수 약 10회
- 군집 1 중심: 월평균구매금액 약 83,000원, 월방문횟수 약 4회
- 군집 2 중심: 월평균구매금액 약 388,000원, 월방문횟수 약 15회

주의사항
K-평균 군집화는 숫자 데이터만 처리할 수 있습니다. 문자열이나 범주형 데이터는 열 선택 노드로 제거해야 합니다.