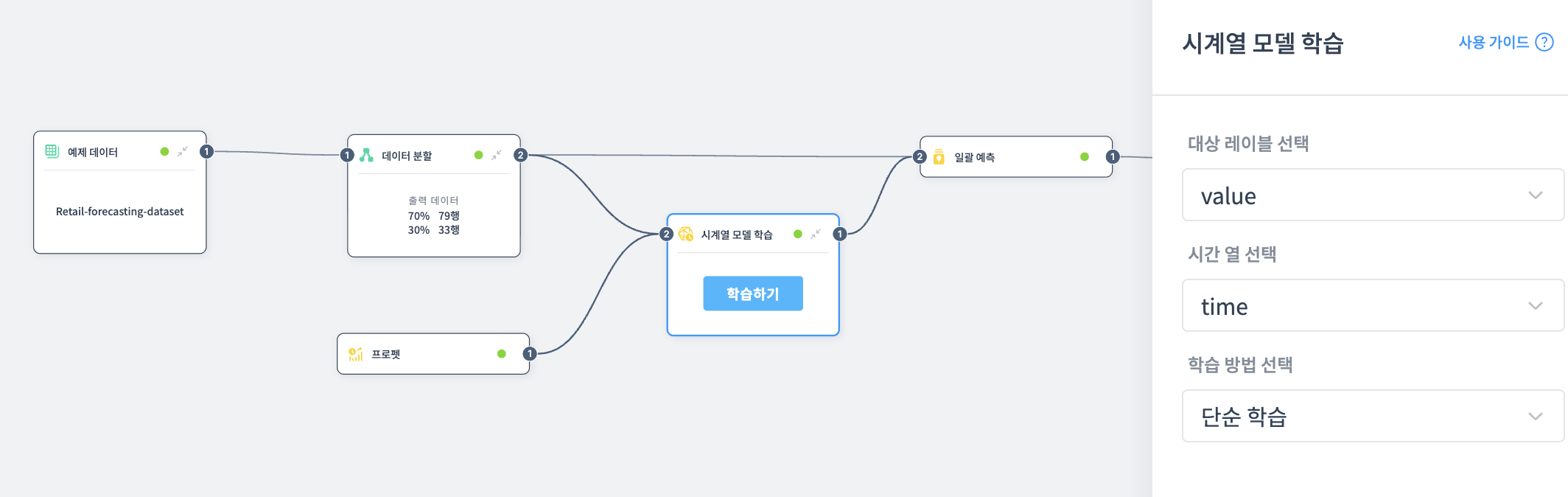
시계열 모델 학습
시계열 데이터를 학습하여 미래 값을 예측하는 모델을 만드는 노드입니다.
설명
시계열 모델 학습 노드는 시간에 따라 변화하는 데이터를 분석하여 미래를 예측하는 모델을 학습합니다.
과거의 패턴과 추세를 학습하여 미래의 값을 예측할 수 있으며, 주가 예측, 수요 예측, 날씨 예측 등에 활용됩니다.
시간 열과 대상 레이블을 지정하고, 다양한 학습 방법을 통해 모델의 성능을 최적화할 수 있습니다.
포트 구성
입력 포트
없음
출력 포트
- 학습된 모델: 학습이 완료된 시계열 모델 (예측 노드에 연결하여 사용)
속성
대상 레이블 선택
예측하고자 하는 대상 열을 선택합니다.
시계열 데이터에서 예측할 값을 지정합니다 (예: 매출, 온도, 주가 등).
시간 열 선택
시계열 데이터가 담긴 열을 선택합니다.
날짜나 시간 정보가 포함된 열을 지정하여 시간 순서를 파악합니다.
학습 방법 선택
모델 학습 및 평가 방법을 선택합니다.
-
단순 학습: 데이터를 학습/테스트로 분할 (예: 70%/30%)
- 빠르고 간단하게 학습 가능
- 데이터 분할에 따라 성능이 달라질 수 있음
-
k-fold 교차 검증: 데이터를 K개 폴드로 나누어 K번 반복 학습
- 전체 데이터를 K개로 나누고, 각 반복에서 K-1개는 학습용, 1개는 테스트용으로 사용
- 모든 폴드가 한 번씩 테스트 데이터로 사용됨
- K번의 평가 결과를 평균하여 안정적이고 신뢰할 수 있는 성능 평가 제공
-
그리드 서치를 통한 하이퍼파라미터 튜닝: 모든 하이퍼파라미터 조합 탐색
- 각 하이퍼파라미터의 후보값을 정의하고, 모든 조합을 시도하여 최적 모델 선택
- 탐색 범위가 작을 때: 간단하고 효과적
- 탐색 범위가 클 때: 계산 비용이 높을 수 있음
사용 방법
- 시계열 모델 학습 노드를 캔버스에 추가합니다
- 시계열 데이터셋을 준비합니다
- 대상 레이블을 선택합니다 (예측할 값)
- 시간 열을 선택합니다 (날짜/시간 정보)
- 학습 방법을 선택합니다
- 노드를 실행하면 학습된 시계열 모델이 출력됩니다
- 학습된 모델을 사용하여 미래 값을 예측할 수 있습니다
예제