데이터 분할
입력받은 데이터셋을 설정한 비율과 방법에 따라 분할합니다.
설명
데이터 분할 노드는 입력받은 데이터셋에서 설정한 분할 비율에 따라 데이터 인스턴스의 하위 집합을 선택하여 데이터를 분할합니다.
샘플링이 완료된 데이터셋과 샘플링된 데이터셋에 포함되지 않은 데이터셋으로 분할하여 두 개의 데이터 테이블을 출력할 수 있습니다. 머신러닝 모델 학습 시 훈련 데이터와 테스트 데이터를 나누거나, 데이터 분석을 위해 샘플을 추출할 때 유용합니다.
포트 구성
입력 포트
- 데이터셋: 분할할 데이터셋
출력 포트
- 데이터셋: 샘플링된 데이터셋
- 데이터셋: 남은 데이터셋
속성
데이터 분할 비율
분할하고 싶은 비율을 입력합니다. (기본값: 0.7)
예를 들어 0.7로 설정하면 전체 데이터의 70%가 첫 번째 출력 포트로, 30%가 두 번째 출력 포트로 분할됩니다.
데이터 분할 방법 선택
데이터를 분할하는 방법을 선택합니다.
- 단순 랜덤: 데이터 포인트를 무작위로 분할합니다
- 계층화: 각 분할에서 전체 데이터셋과 동일한 비율의 카테고리를 유지합니다 (한 카테고리의 데이터가 다른 카테고리보다 많은 경우에 유용합니다)
- 시계열 분할: 시간 순서를 고려하여 분할합니다
사용 방법
- 데이터셋을 입력 포트에 연결합니다
- 데이터 분할 비율을 설정합니다 (예: 0.7)
- 데이터 분할 방법을 선택합니다
- 노드가 실행되면 두 개의 출력 포트에서 분할된 데이터셋을 확인할 수 있습니다
- 다른 노드와 연결할 때 노드 연결 설정에서 원하는 출력을 선택합니다
예제
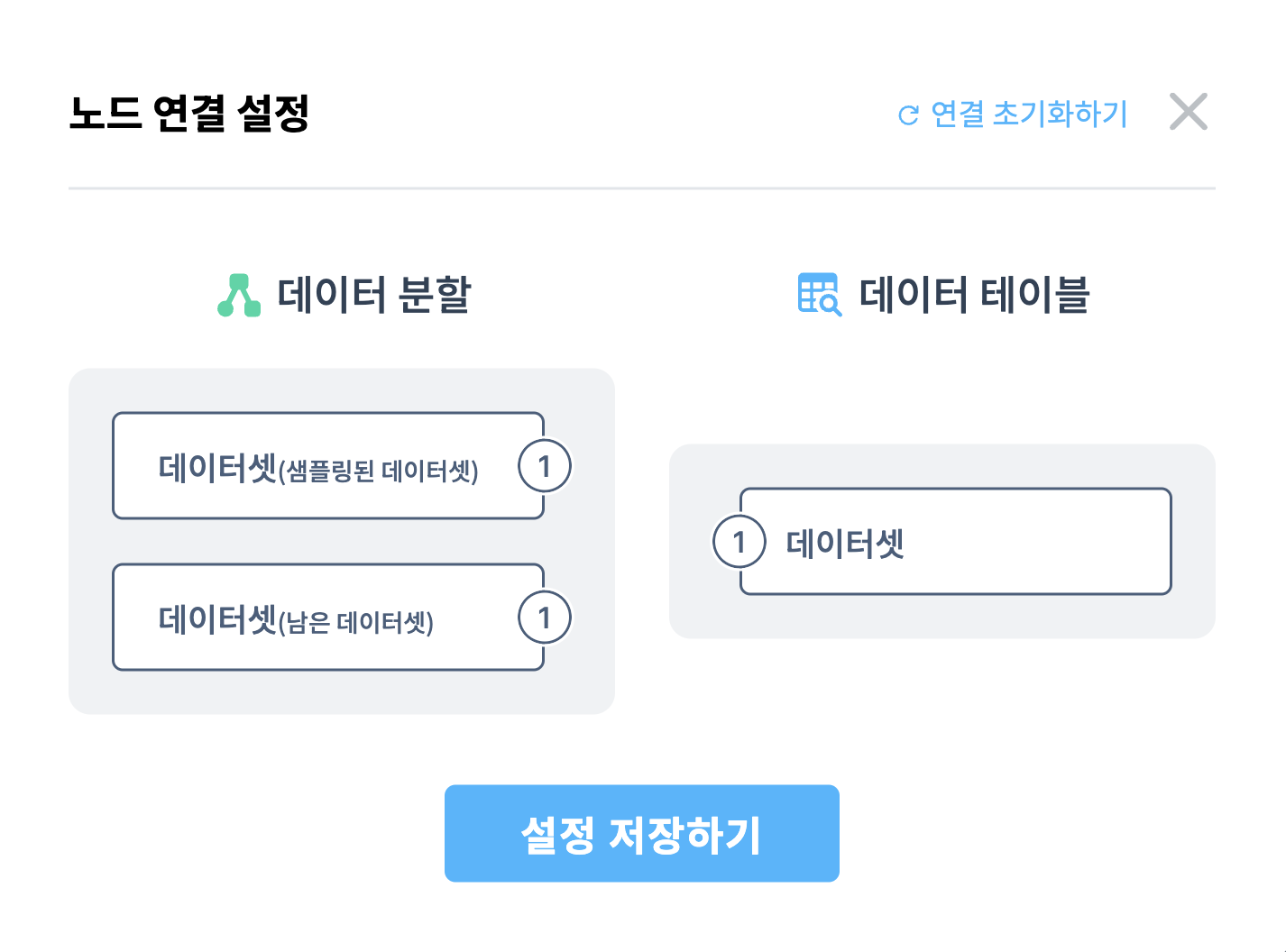
노드 연결 설정
데이터 분할 노드를 다른 노드의 입력 포트와 연결할 때, 두 개의 출력 포트 중 어느 것을 연결할지 선택할 수 있는 노드 연결 설정 팝업이 표시됩니다.
- 샘플링된 데이터셋: 분할 비율에 따라 선택된 데이터
- 남은 데이터셋: 샘플링에 포함되지 않은 나머지 데이터