특성 중요도
모델의 변수 중요도를 확인하는 노드입니다.
설명
특성 중요도 노드는 모델이 예측할 때 각 변수(특성)가 예측값에 얼마나 기여하는지를 백분율로 나타내는 도구입니다.
특성 중요도란?
특성 중요도는 모델의 예측 결과에 각 특성이 얼마나 영향을 미치는지를 수치화한 것입니다. 특정 특성의 값이 변할 때 모델의 예측이 얼마나 달라지는지를 측정하여, 해당 특성이 예측에 얼마나 중요한 역할을 하는지 판단합니다.
활용 예시
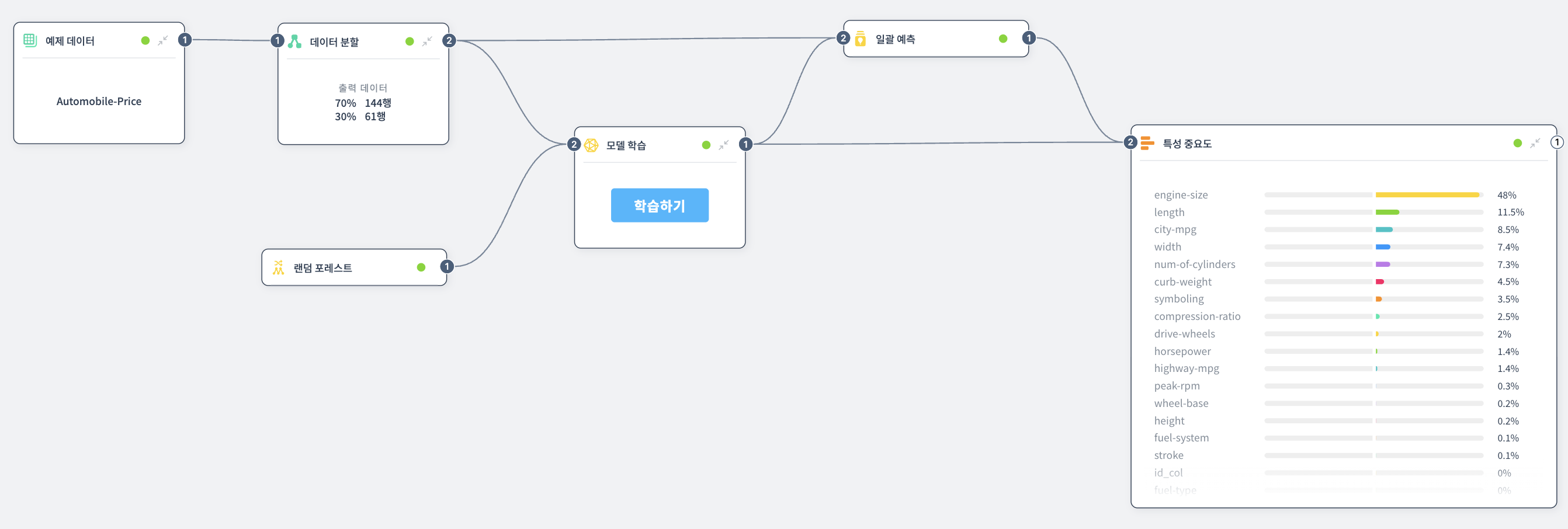
자동차 가격 예측 모델
자동차 가격을 예측하는 모델에서 특성 중요도를 분석한 결과:
engine-size열의 특성 중요도: 48%length열의 특성 중요도: 11.5%city-mpg열의 특성 중요도: 8.5%width열의 특성 중요도: 7.4%num-of-cylinders열의 특성 중요도: 7.3%id_col,fuel type열의 특성 중요도: 0%
이 결과를 해석하면:
engine-size는 자동차 가격 예측에 가장 중요한 특성으로, 전체 예측의 약 **48%**를 차지합니다.length,city-mpg,width,num-of-cylinders등이 그 다음으로 중요한 특성들입니다.id_col과fuel type은 특성 중요도가 **0%**이므로, 이 특성들은 예측에 거의 영향을 주지 않습니다. 따라서 모델에서 제거해도 성능에 큰 영향이 없을 수 있습니다.- "자동차가 왜 비싼가?"라는 질문에 대한 답은 엔진 크기가 가장 큰 요인임을 데이터 기반으로 확인할 수 있습니다.
특성 중요도의 활용
특성 중요도 분석을 통해 다음과 같은 인사이트를 얻을 수 있습니다:
- 예측 요인 파악: 예측 결과에 가장 큰 영향을 미치는 특성을 식별합니다.
- 모델 해석: 모델이 어떤 특성을 기반으로 예측하는지 이해할 수 있습니다.
- 특성 선택: 중요도가 낮은 특성을 제거하여 모델을 단순화하거나 성능을 개선할 수 있습니다.
- 비즈니스 인사이트: 예측 결과의 원인을 파악하여 의사결정에 활용할 수 있습니다.
포트 구성
입력 포트
- 학습된 모델: 학습이 완료된 모델 (모델 학습 노드의 출력)
- 데이터셋: 모델 학습에 사용된 데이터
출력 포트
- 데이터셋: 각 특성(feature)의 중요도를 나타내는 값들이 포함된 데이터셋
출력 데이터셋
| 컬럼명 | 설명 |
|---|---|
| column_name | 특성(열)의 이름 |
| importances_mean | 특성 중요도의 평균값 |
| importances_std | 특성 중요도의 표준 편차 |
| importances_percent(%) | 전체에서 해당 특성의 중요도가 차지하는 비율(%) |
사용 방법
- 특성 중요도 노드를 캔버스에 추가합니다
- 모델 학습 노드의 출력(학습된 모델)을 첫 번째 입력 포트에 연결합니다
- 모델 학습에 사용된 데이터셋을 두 번째 입력 포트에 연결합니다
- 노드를 실행하면 각 특성의 중요도가 계산되어 출력 데이터셋으로 제공됩니다
- 출력 데이터셋을 확인하여 어떤 특성이 예측에 가장 중요한 영향을 미치는지 분석합니다
예제